Entry No. 17
What is ReactiveList A built-in class come along with ReactiveUI to replace ObservableCollection. It is similar to a list but has the power of Rx. But it...
Entry No. 16
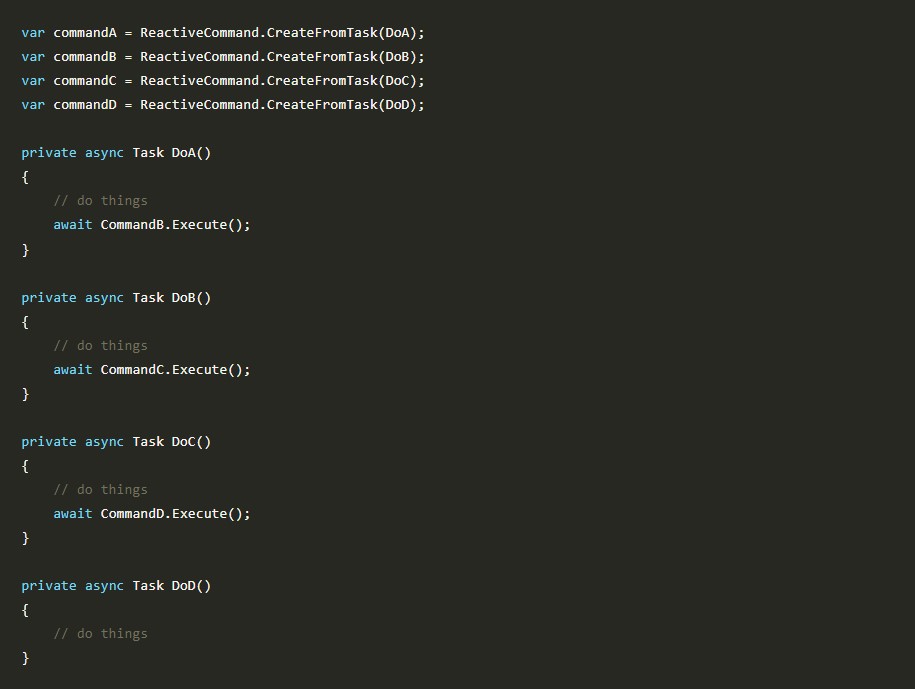
What is it? ReactiveCommand is a Reactive Extensions and asynchronous aware implementation of the ICommand interface and can be executed either synchronously or asynchronously. What is it...
Entry No. 15
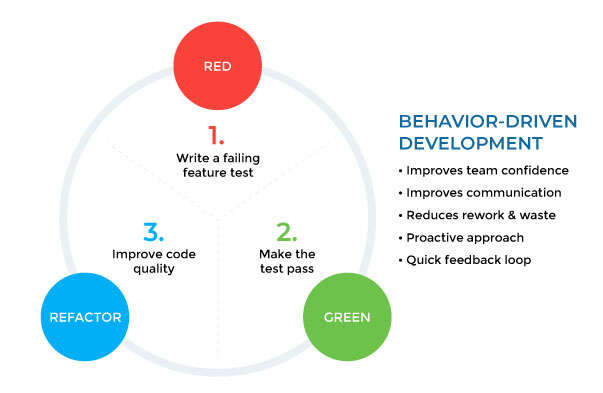
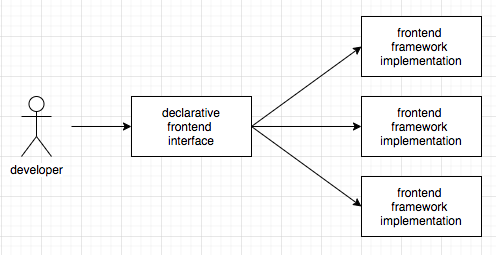
If you are working on XAML in C#, you must know the MVVM pattern. To achieve this, to make the View “react” to the changes in ViewModel,...
Entry No. 14
Origin One week ago, our FCS QA/QC mentioned that the pagination info we displayed does not tally with the number of items we listed. Originally, I thought...
Entry No. 13
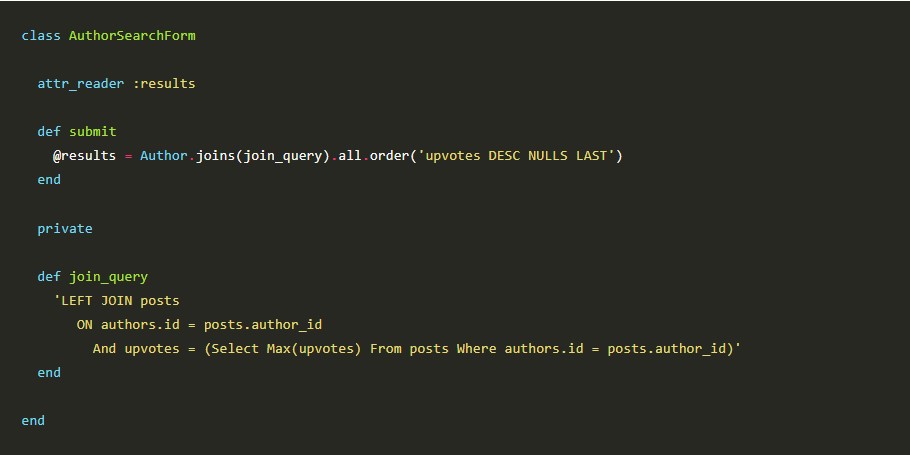
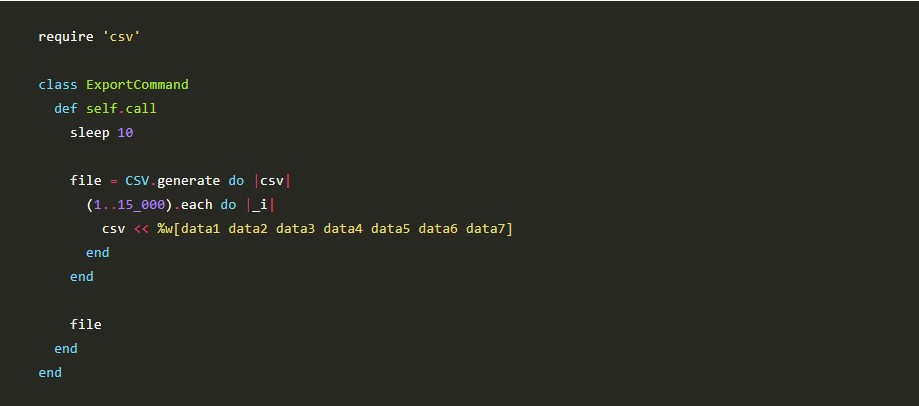
Situation Overview Exporting data was a nightmare to us all at FCS. We used to have it running directly in the controller, which causes system crash when...
Entry No. 12
A memorable Friday It was a Friday morning and the end of a sprint too. I had already submitted my code for the second task the night...
Entry No. 11
There are 3 skill sets in this industry – development, design and product. These skills exist in every attempt to build software. They exist in Google, and...
Entry No. 10
When I first told my parents that I wanted to study computer science, my father took me aside and asked me: “Are you sure? The computer industry...
Entry No. 9
We’ve had a number of technical interns here in FCS over the years. Some do really well: by the end of their internships they find themselves delivering...
Entry No. 8
This short document will outline some skills and attitudes that would help you with your engineering career at Floating Cube. Engineers receive this document during orientation. Floating...
Entry No. 7
When doing recruiting for Floating Cube Studios, I’ve found it rare to find students who have had side projects. Most of the candidates I’ve interviewed have only...
Entry No. 6
One of the most surprising things I’ve learnt about software engineers in Saigon is that many want to specialise in just one programming language or platform. This...
Entry No. 5
Profit centres vs cost centres is something I wish someone had told me earlier in my career. This idea applies to just about any job you do,...
Entry No. 4
As a fresh graduate, should you go after a high-paying job, or look for places you can grow? My answer to this is deceptively simple: so long...
Entry No. 3
If you’re a software engineer in Vietnam, there are 4 types of companies you can work for. These companies exist on a spectrum of value. As you...
Entry No. 2
It’s been 5 years since Floating Cube Studios first set up in Singapore and Saigon. We’ve gone though quite a bit since then: built apps for clients...
Entry No. 1
Body text for the blog section will be a 10-columns centered container. The font will be Georgia to enhance the legibility of the blog post. Let’s have...